
Today I decided to test Deepseek-R1 on my old laptop with Ubuntu. In this article I will describe the steps that I used to run the model.
Ollama
First of all you need to install Ollama that will allow you to run queries to your language model.
Here is the official website: https://ollama.com/
The installation is quite simple, just run the next command that you can find in the official documentation
curl -fsSL https://ollama.com/install.sh | shAfter the installation you will probably asked to reboot your computer to apply the changes.
Because Ollama installed as a system service you can verify the status via basic systemctl command like this
$ systemctl status ollamaYou will see something like this, that says that the service is running
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Sat 2025-02-01 12:53:22 CET; 6s ago
Main PID: 81326 (ollama)
Tasks: 9 (limit: 18973)
Memory: 15.5M (peak: 19.8M)
CPU: 154ms
CGroup: /system.slice/ollama.service
└─81326 /usr/local/bin/ollama serve
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: [GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
Feb 01 12:53:22 laptop ollama[81326]: time=2025-02-01T12:53:22.689+01:00 level=INFO source=routes.go:1238 msg="Listening on 127.0.0.1:11434 (version 0.5.7)"
Feb 01 12:53:22 laptop ollama[81326]: time=2025-02-01T12:53:22.689+01:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cuda_v11_avx cuda_v12_avx rocm_avx c>
Feb 01 12:53:22 laptop ollama[81326]: time=2025-02-01T12:53:22.689+01:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
Feb 01 12:53:22 laptop ollama[81326]: time=2025-02-01T12:53:22.775+01:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-5d63bf43-e4e2-eac1-6ce6-3c667ddad3a8 library=Pay attention that the service is enabled by default, so if you want to change this you need to disable it and then run manually whenever you need it.
To remove from autostart
$ systemctl disable ollamaTo return back to autostart
$ systemctl enable ollamaTo start/stop/restart service
$ systemctl start ollama
$ systemctl stop ollama
$ systemctl restart ollamaDeepSeek language model
Now you need to download the model. The Deepseek models ids can be found on the next page
As you can see on this page we can use different models that have different amount of parameters, and as result the size
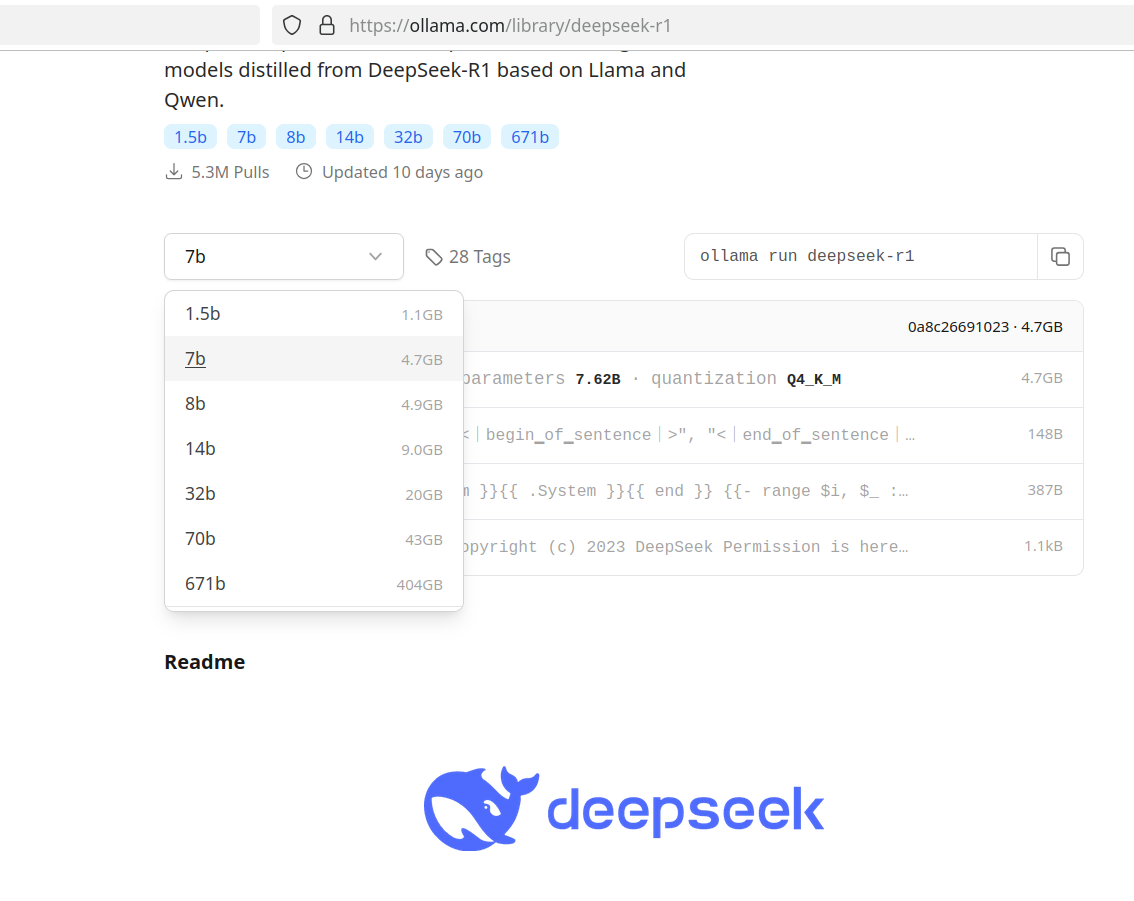
in this example we will use 7b, but you can choose another one.
So let’s download and run the model, for this we need to execute next command
$ ollama run deepseek-r1if you want to download particular model, just use the full name of this model, for example
$ ollama run deepseek-r1:8bIt makes sense to use a model that can be fully loaded into your GPU’s video memory. For example, if you have 6GB of VRAM, using an 8B model (4.7GB) is a good choice. If you have 12GB of VRAM, the 14B model (9GB) would be better suited for your needs. For a high-end GPU like the RTX 3090 with 24GB of VRAM, the 32B model (20GB) would be an excellent choice.
After the model downloaded you will see the prompt where you can chat with the model
$ ollama run deepseek-r1
pulling manifest
pulling 96c415656d37... 100% ▕████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>> What is the value of 3/2?
<think>
To determine the value of three halves, I start by dividing three by two. This division results in one and a half.
Therefore, the value of \( \frac{3}{2} \) is 1.5.
</think>
To find the value of \(\frac{3}{2}\), follow these simple steps:
1. **Divide 3 by 2:**
\[
\frac{3}{2} = 1.5
\]
So, the value of \(\frac{3}{2}\) is \(\boxed{1.5}\).
You can use “/?” to see available commands
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.So, to exit from the prompt to console just use next the
>>> /byeTo re-enter to the prompt run again
$ ollama run deepseek-r1Ollama API
As I already said by default Ollama started as a service which means that even if you exit from the prompt it will run in background and we can send basic HTTP requests to the service.
The host is localhost and default port is 11434
API documentation can be found in GitHub: https://github.com/ollama/ollama/blob/main/docs/api.md
Here is example of the request via CURL
$ curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1", "prompt": "What is water made of?" }'
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:41.051522265Z","response":"\u003cthink\u003e","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:41.439529668Z","response":"\n","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:41.813337097Z","response":"Okay","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:42.23330141Z","response":",","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:42.613174133Z","response":" so","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:42.99222421Z","response":" I","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:43.366673308Z","response":" need","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:43.780126163Z","response":" to","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:44.248825038Z","response":" figure","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:44.697102907Z","response":" out","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:45.085694522Z","response":" what","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:45.462899245Z","response":" water","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:45.887284527Z","response":" is","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:46.287477272Z","response":" made","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:46.666379599Z","response":" of","done":false}
{"model":"deepseek-r1","created_at":"2025-02-01T11:09:47.063913034Z","response":".","done":false}
Open Web UI
Open Web UI is an GUI interface similar to ChatGPT web ui.
- The official website is: https://openwebui.com/
- GitHub: https://github.com/open-webui/open-webui
For the installation I will use Docker, so you need to install it if it’s not installed
https://docs.docker.com/engine/install/ubuntu/#install-using-the-repositoryAfter the docker installation pull the main image
$ docker pull ghcr.io/open-webui/open-webui:mainIf you have Nvidia videocard that supports CUDA pull the “cuda” image
$ docker pull ghcr.io/open-webui/open-webui:cudaAfter the pulling just run the next command that will start docker container
$ docker run --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Loading WEBUI_SECRET_KEY from file, not provided as an environment variable.
Generating WEBUI_SECRET_KEY
Loading WEBUI_SECRET_KEY from .webui_secret_key
/app/backend/open_webui
/app/backend
/app
Running migrations
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [open_webui.env] 'ENABLE_OLLAMA_API' loaded from the latest database entry
INFO [open_webui.env] 'OLLAMA_BASE_URLS' loaded from the latest database entry
INFO [open_webui.env] 'OLLAMA_API_CONFIGS' loaded from the latest database entry
INFO [open_webui.env] 'ENABLE_OPENAI_API' loaded from the latest database entry
INFO [open_webui.env] 'OPENAI_API_KEYS' loaded from the latest database entry
INFO [open_webui.env] 'OPENAI_API_BASE_URLS' loaded from the latest database entry
INFO [open_webui.env] 'OPENAI_API_CONFIGS' loaded from the latest database entry
INFO [open_webui.env] 'ENABLE_SIGNUP' loaded from the latest database entry
INFO [open_webui.env] 'DEFAULT_LOCALE' loaded from the latest database entry
INFO [open_webui.env] 'DEFAULT_MODELS' loaded from the latest database entry
INFO [open_webui.env] 'DEFAULT_PROMPT_SUGGESTIONS' loaded from the latest database entry
INFO [open_webui.env] 'MODEL_ORDER_LIST' loaded from the latest database entry
WARNI [open_webui.env]
WARNING: CORS_ALLOW_ORIGIN IS SET TO '*' - NOT RECOMMENDED FOR PRODUCTION DEPLOYMENTS.
INFO [open_webui.env] Embedding model set: sentence-transformers/all-MiniLM-L6-v2
WARNI [langchain_community.utils.user_agent] USER_AGENT environment variable not set, consider setting it to identify your requests.
___ __ __ _ _ _ ___
/ _ \ _ __ ___ _ __ \ \ / /__| |__ | | | |_ _|
| | | | '_ \ / _ \ '_ \ \ \ /\ / / _ \ '_ \| | | || |
| |_| | |_) | __/ | | | \ V V / __/ |_) | |_| || |
\___/| .__/ \___|_| |_| \_/\_/ \___|_.__/ \___/|___|
|_|
v0.5.7 - building the best open-source AI user interface.
https://github.com/open-webui/open-webui
Fetching 30 files: 100%|██████████| 30/30 [00:00<00:00, 31631.25it/s]
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)Open your browser and navigate to http://localhost:8080 . On first run you will be asked to create the admin account by entering email and password.
After you create an account you will be able to log in and start the chat.
If the model is not appeared then go to settings and check connection with ollama.
If you have a slow laptop like mine you can face the “Network Problem” error. If it’s so try to wait some time, the response will appear after will be generated. You can measure the average response time by using Ollama Prompt or API first. This problem will look like
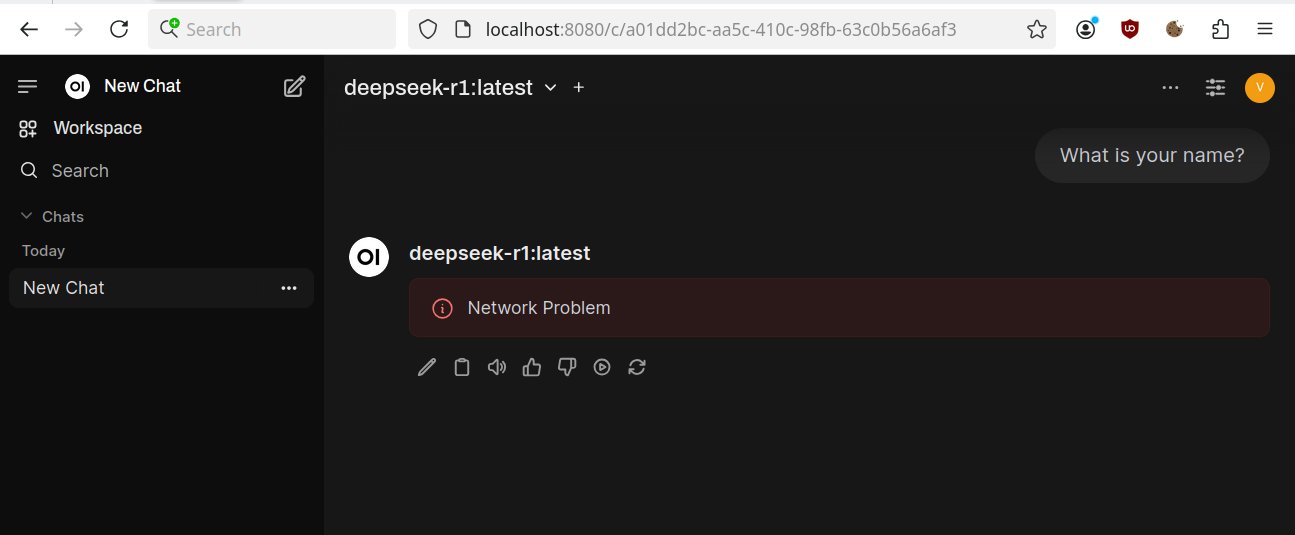
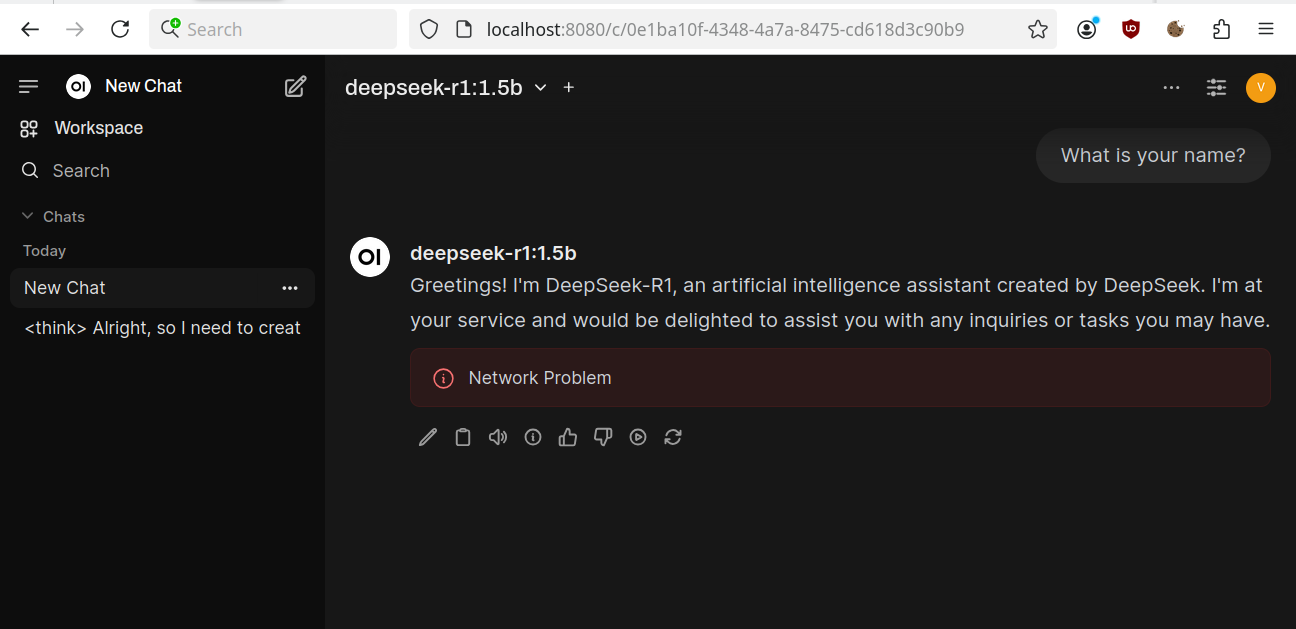
Other. Videocard information
The videocard compatibility with Ollama can be checked here: https://github.com/ollama/ollama/blob/main/docs/gpu.md .
The load of the Nvidia videocard can be checked with the utility nvidia-smi, just run it in terminal and you can monitor memory usage and GPU utilisation, here is example of my GTX 1660 TI
$ nvidia-smi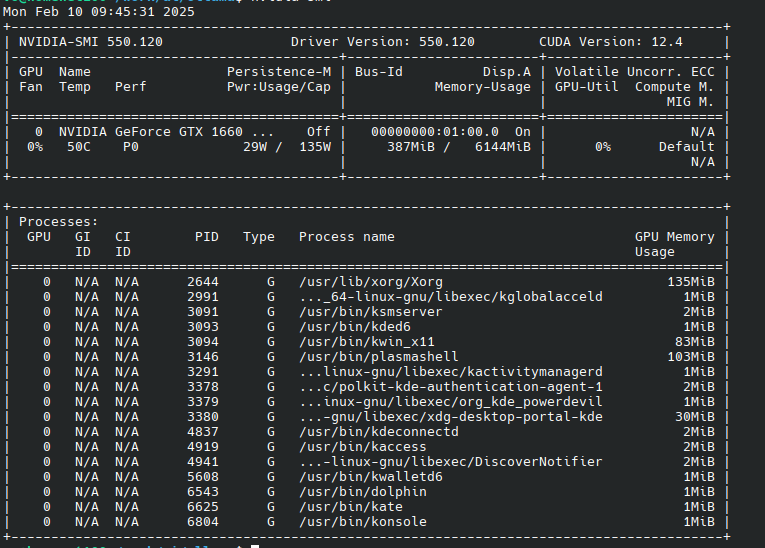
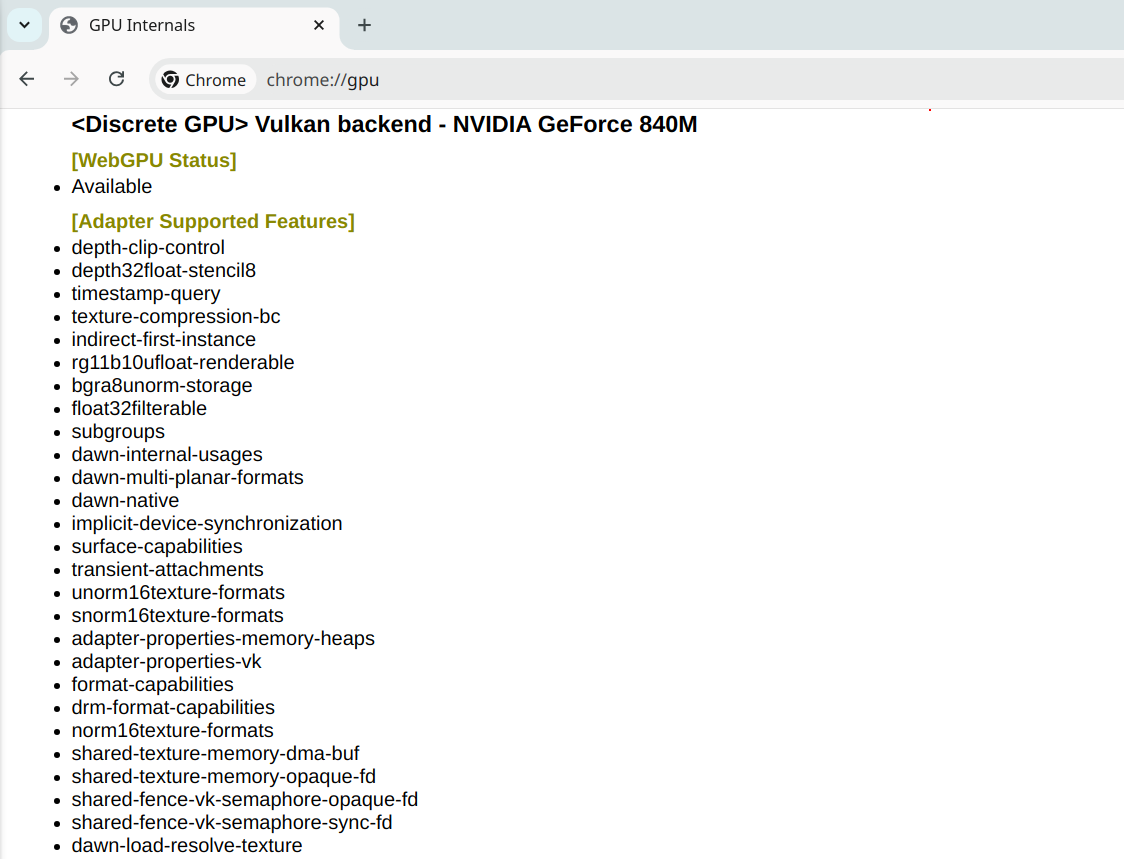
You can also get info about your card in other formats, for example run next to get you videocard model
$ nvidia-smi --query-gpu=name --format=csv
name
NVIDIA GeForce 840MYou can also use Chrome to quickly get info by using “chrome://gpu/” as an URL
Other. Ollama CLI commands
- ollama serve = Starts Ollama on your local system.
- ollama create = Creates a new model from an existing one for customization or training.
- ollama show = Displays details about a specific model, such as its configuration and release date.
- ollama run = Runs the specified model, making it ready for interaction
- ollama pull = Downloads the specified model to your system.
- ollama list = Lists all the downloaded models.
- ollama ps = Shows the currently running models.
- ollama stop = Stops the specified running model.
- ollama rm = Removes the specified model from your system.
Other. Ollama system information
You can get some system information about current Ollama status by using next command
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:1.5b a42b25d8c10a 1.9 GB 100% GPU 4 minutes from now Here we have next columns:
- NAME = loaded model name
- ID = loaded model ID
- SIZE = size of the model
- PROCESSOR = indicates where the model is loaded:
- 100% GPU: The model is fully loaded into the GPU.
- 100% CPU: The model is fully loaded into system memory.
- 48%/52% CPU/GPU: The model is partially loaded onto both the GPU and system memory
- UNTIL = The time remaining until the model is unloaded from memory